
Four of these papers are from Prof. Achuta Kadambi’s lab and one is from Prof. Mani Srivastava’s lab.
Paper 1:
WeatherStream: Light Transport Automation of Single Image Deweathering
Howard Zhang, Yunhao Ba, Ethan Yang, Varan Mehra, Blake Gella, Akira Suzuki, Arnold Pfahnl, Chethan Chinder Chandrappa, Alex Wong and Achuta Kadambi.

Abstract
Today single image deweathering is arguably more sensitive to the dataset type, rather than the model. We introduce WeatherStream, an automatic pipeline capturing all real-world weather effects (rain, snow, and rain fog degradations), along with their clean image pairs. Previous state-of-the-art methods that have attempted the all-weather removal task train on synthetic pairs, and are thus limited by the Sim2Real domain gap. Recent work has attempted to manually collect time multiplexed pairs, but the use of human labor limits the scale of such a dataset. We introduce a pipeline that uses the power of light-transport physics and a model trained on a small, initial seed dataset to reject approximately 99.6% of unwanted scenes. The pipeline is able to generalize to new scenes and degradations that can, in turn, be used to train existing models just like fully human-labeled data. Training on a dataset collected through this procedure leads to significant improvements on multiple existing weather removal methods on a carefully human-collected test set of real-world weather effects.
Paper 2:
ALTO: Alternating Latent Topologies for Implicit 3D Reconstruction
Zhen Wang, Shijie Zhou, Jeong Joon Park, Despoina Paschalidou, Suya You, Gordon Wetzstein, Leonidas Guibas, Achuta Kadambi.

Abstract
This work introduces alternating latent topologies (ALTO) for high-fidelity reconstruction of implicit 3D surfaces from noisy point clouds. Previous work identifies that the spatial arrangement of latent encodings is important to recover detail. One school of thought is to encode a latent vector for each point (point latents). Another school of thought is to project point latents into a grid (grid latents) which could be a voxel grid or triplane grid. Each school of thought has tradeoffs. Grid latents are coarse and lose high-frequency detail. In contrast, point latents preserve detail. However, point latents are more difficult to decode into a surface, and quality and runtime suffer. In this paper, we propose ALTO to sequentially alternate between geometric representations, before converging to an easy-to-decode latent. We find that this preserves spatial expressiveness and makes decoding lightweight. We validate ALTO on implicit 3D recovery and observe not only a performance improvement over the state-of-the-art, but a runtime improvement of 3-10 times.
Paper 3:
pCON: Polarimetric Coordinate Networks for Neural Scene Representations
Henry Peters, Yunhao Ba and Achuta Kadambi.
Abstract
Neural scene representations have achieved great success in parameterizing and reconstructing images, but current state of the art models are not optimized with the preservation of physical quantities in mind. While current architectures can reconstruct color images correctly, they create artifacts when trying to fit maps of polar quantities. We propose polarimetric coordinate networks (pCON), a new model architecture for neural scene representations aimed at preserving polarimetric information while accurately parameterizing the scene. Our model removes artifacts created by current coordinate network architectures when reconstructing three polarimetric quantities of interest.
Paper 4:
Depth Estimation from Camera Image and mmWave Radar Point Cloud
Akash Deep Singh, Yunhao Ba, Ankur Sarker, Howard Chenyang Zhang, Achuta Kadambi, Stefano Soatto, Mani Srivastava, Alex Wong.
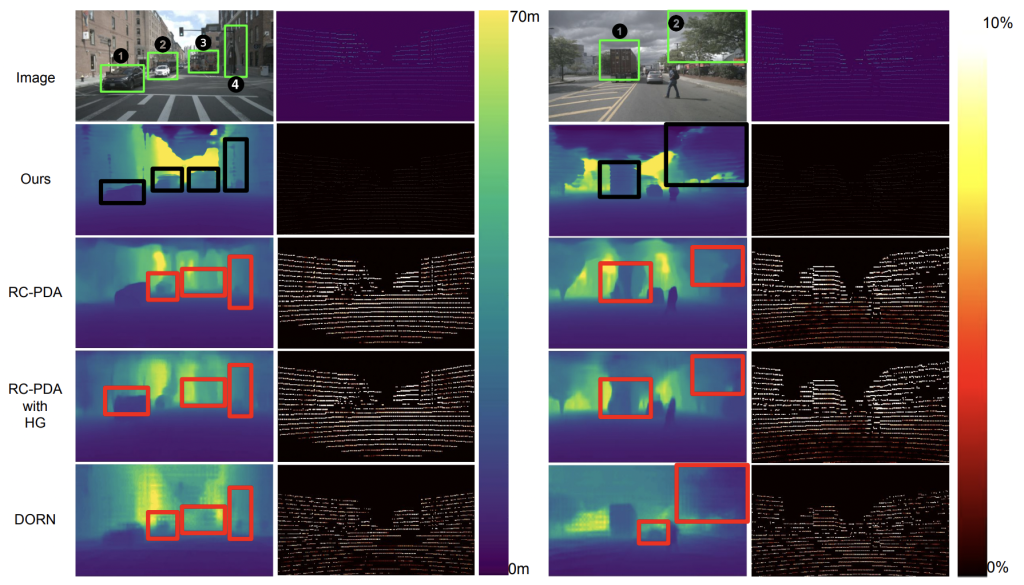
Abstract
We present a method for inferring dense depth from a camera image and a sparse noisy radar point cloud. We first describe the mechanics behind mmWave radar point cloud formation and the challenges that it poses, i.e. ambiguous elevation and noisy depth and azimuth components that yields incorrect positions when projected onto the image, and how existing works have overlooked these nuances in camera-radar fusion. Our approach is motivated by these mechanics, leading to the design of a network that maps each radar point to the possible surfaces that it may project onto in the image plane. Unlike existing works, we do not process the raw radar point cloud as an erroneous depth map, but query each raw point independently to associate it with likely pixels in the image – yielding a semi-dense radar depth map. To fuse radar depth with an image, we propose a gated fusion scheme that accounts for the confidence scores of the correspondence so that we selectively combine radar and camera embeddings to yield a dense depth map. We test our method on the NuScenes benchmark and show a 10.3% improvement in mean absolute error and a 9.1% improvement in root-mean-square error over the best method.